Fixing flow model evals
Flow models are a very promising alternative to autoregression in language modeling, especially in the few-step regime. Yet, the current standard for evaluating these models -- generative perplexity and entropy -- is broken:
- It is trivial to generate "SOTA" results by trading off a little entropy for a lot of PPL
- The best-scoring model is not the best language model, but the most
gpt2-large-like - Entropy only measures intra-sample diversity: inter-sample diversity is an afterthought
Here, I will demonstrate each of these issues and their implications (Section: Issues). Each issue can be somewhat ameliorated, but the entire framework should be abandoned in favor of perplexity bounds and downstream metrics (Section: Fixes).
Meta note: I purposefully focus on a result that is not the main figure for most papers (1024 integration steps) because it makes comparisons to AR models and discrete diffusions easier. All of the main points hold in the few step setting.
Background: how to measure generative perplexity and sample entropy
The issues
1. It is trivial to generate "SOTA" results by trading off a little entropy for a lot of PPL
There is a fundamental tradeoff between generative perplexity and entropy. Generative perplexity is measuring how unpredictable the sequence is under some scoring model (almost always gpt2-large) and entropy is measuring how unpredictable the sequence is based on unigram counts. So, it would be unsurprising if a knob which decreases entropy also decreases generative perplexity.
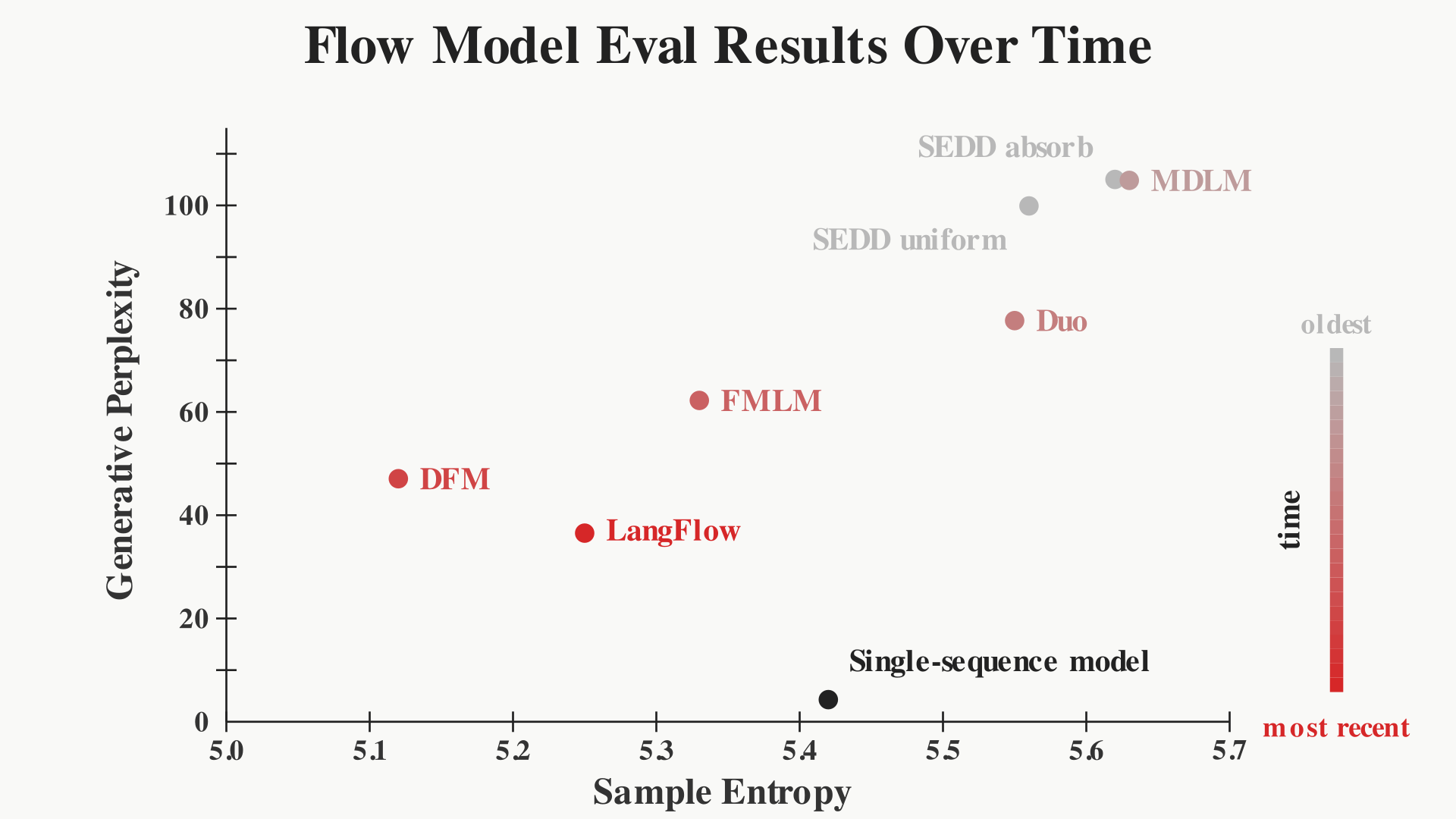
When reporting results with generative perplexity and entropy, nearly all recent papers will have variation in the entropy of their model and the baselines. In fact, if we compile three recent SOTA flow model papers (FMLM, DFM, LangFlow) and their diffusion baselines (Duo, MDLM, SEDD) with reported NFE=1024 on OpenWebText (OWT), notice that generative perplexity gets significantly better, dropping from 105.03 for SEDD to 36.53 for LangFlow, but entropy also decreases from 5.62 to 5.25.
| model | release date | gen. PPL | entropy |
|---|---|---|---|
| SEDD-absorbing | 2023-10-25 | 105.03 | 5.62 |
| MDLM | 2024-11-10 | 104.85 | 5.63 |
| SEDD-uniform | 2023-10-25 | 99.90 | 5.56 |
| Duo | 2025-06-12 | 77.69 | 5.55 |
| FMLM ★ | 2026-02-18 | 62.23 | 5.33 |
| DFM ★ | 2026-04-10 | 47.07 | 5.12 |
| LangFlow ★ | 2026-04-15 | 36.53 | 5.25 |
Reported OWT results at NFE=1024 show lower generative perplexity paired with lower entropy across later methods. ★ = flow model.
Generative perplexity and entropy for recent flow and diffusion language models, shown chronologically (NFE=1024).
Are these improvements in generative perplexity from better models of the data or because they generate lower entropy samples with default sampling parameters?
We can answer this question by sweeping the sampling temperature of the diffusion models. All of the results above are with temperature t=1. But when we unmask a token, we can sample that token with arbitrary t: low temperatures will give us low gen. PPL / low entropy samples, and high temperatures will give us high gen. PPL / high entropy samples (just like in autoregressive models).
If we sweep sampling temperatures for SEDD/MDLM/Duo and measure the gen. PPL and entropy for the resulting samples, we get the following:
As you can see, the improvements in generative perplexity are much more marginal than they appear on a first read. Comparing LangFlow to SEDD-absorb without adjusting the temperatures seems like a nearly 3x decrease in gen. PPL, but an entropy-matched SEDD-absorb baseline is only ~10% higher gen. PPL.
Sampling from SEDD (a 2023 paper) with t=0.88 would have the lowest generative perplexity of all reported results, and its entropy would be within the reported ranges -- a SOTA result! By changing the sampling temperature slightly, the method has gone from the worst (highest gen. PPL) to the best.
Aside: to be very clear, there has been great progress in flow models and diffusions: getting flow models to work at all in text is new, the result from above is with NFE=1024 whereas flow model's benefits are at much lower NFEs, and gen. PPL has issues even when fixing entropy (see later sections). We purposefully focus on the non-main result to make clear that we are pointing out issues with the evaluation framework rather than any specific paper.
Next, we give evidence (beyond our earlier-stated intuition) that matching entropy is the right thing to do.
Why match entropy: experiments with GPT-2
The GPT-2 family of models established a very clean scaling trend: as we scale from gpt2-small to gpt2-medium to gpt2-large to gpt2-xl, the validation perplexity and accuracy smoothly improve on all measured domains. However, if we sample from the GPT-2 models at default settings and measure generative perplexity, the scaling is no longer clean: gpt2-small is better than gpt2-medium, and gpt2-large is better than gpt2-xl.
| model | OWT val. ppl | gen. PPL | entropy (data=5.44) |
|---|---|---|---|
| gpt2-small (124M) | 24.7004 | 122.3149 | 5.8842 |
| gpt2-medium (355M) | 18.5578 | 193.0853 | 6.0724 |
| gpt2-large (774M) | 15.6704 | 35.9183 | 5.7023 |
| gpt2-xl (1.6B) | 14.0935 | 41.2730 | 5.7145 |
Gold, silver, and copper mark the best, second-best, and third-best generative perplexity scores. Note the disagreement between the OWT validation perplexity and the generative perplexity.
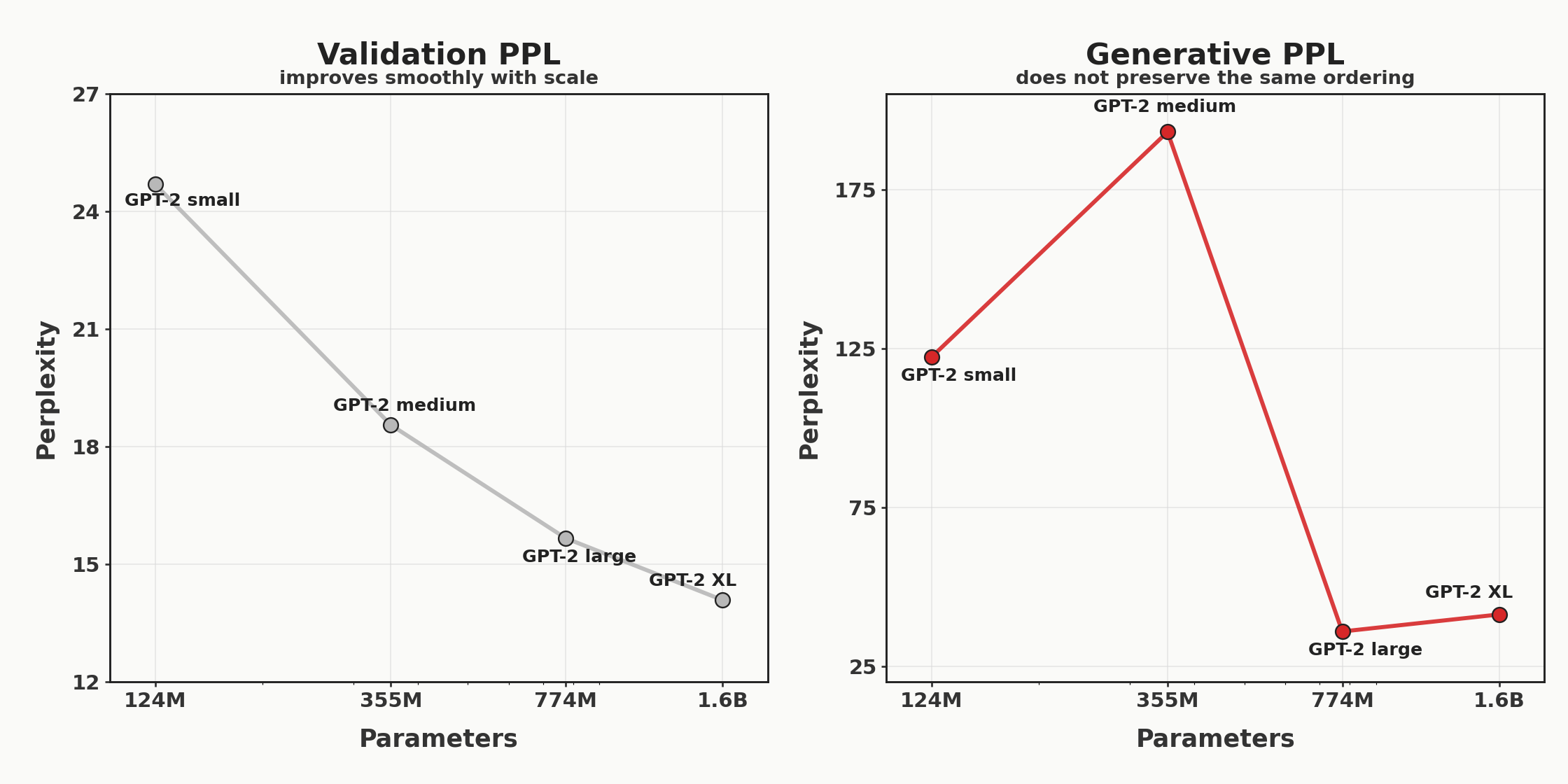
GPT-2 validation perplexity on OpenWebText (left) improves with scale, but generative perplexity under gpt2-large (right) does not preserve the same ordering (N=128 samples, temp=1).
This should raise a red flag: the standard evaluation for flow models does not track the scaling of GPT-2 models. If we plot this same data in the same way we presented the flow/diffusion results -- scattering gen. PPL v. entropy -- we notice the same trend as before: generative perplexity increases with entropy.
In the GPT-2 models, there seems to be a tradeoff between sample entropy and generative perplexity.
| model | OWT val. ppl | gen. PPL | entropy (data=5.44) |
|---|---|---|---|
| gpt2-small (124M) | 24.7004 | 122.3149 | 5.8842 |
| gpt2-medium (355M) | 18.5578 | 193.0853 | 6.0724 |
| gpt2-large (774M) | 15.6704 | 35.9183 | 5.7023 |
| gpt2-xl (1.6B) | 14.0935 | 41.2730 | 5.7145 |
Gold, silver, and copper mark the best, second-best, and third-best generative perplexity scores. Note the disagreement between the OWT validation perplexity and the generative perplexity.
Let's see if these entropy differences can explain why samples from gpt2-medium have a worse generative perplexity than samples from gpt2-small. Like in diffusion models, we can treat the sampling temperature as an "entropy knob": lower temperature generations create low entropy/low gen. PPL samples, and higher temperature generations create high entropy/high gen. PPL samples. Below, we sweep sampling from gpt2-small and gpt2-medium with t=0.5 to t=1 and plot the gen. PPL vs. entropy for each temperature.
gpt2-small and gpt2-medium at various sampling temperatures. Each point is the average gen. PPL / entropy from 128 samples at a given sampling temperature. When entropy-matched, we recover that gpt2-medium > gpt2-small, when temperature-matched, one would conclude that gpt2-small > gpt2-medium.
So the generative perplexity is incredibly sensitive to entropy. If we match the sampling parameters, gpt2-small has a better gen. PPL (this is bad). If we match the entropy, gpt2-medium has a better gen. PPL (this is good). In the earlier plot, we were temperature matching: explaining why we measured gpt2-small as being the better model.
Let's look at an even more extreme example of the erroneous conclusions that an unaccounted-for entropy difference can cause. From our previous plot, we can derive that if we sample gpt2-small with temp=0.91, we will generate samples with roughly the same entropy as the actual data: 5.44 nats. At this entropy, gpt2-xl will have a lower gen. PPL, but there is some entropy where it has a higher gen. PPL. How much entropy do we have to add to get there?
gpt2-xl look worse than gpt2-small under generative perplexity.The answer is 0.23 nats.
That 0.23-nat gap is small compared to the entropy spread seen within single recent flow-model papers across their reported baselines and methods:
gpt2-xl below gpt2-small under gen. PPL.To be clear, this means that the typical entropy variance between models and baselines in recent results is permissive enough to show that gpt2-small is better than gpt2-xl.
What this means for interpreting results
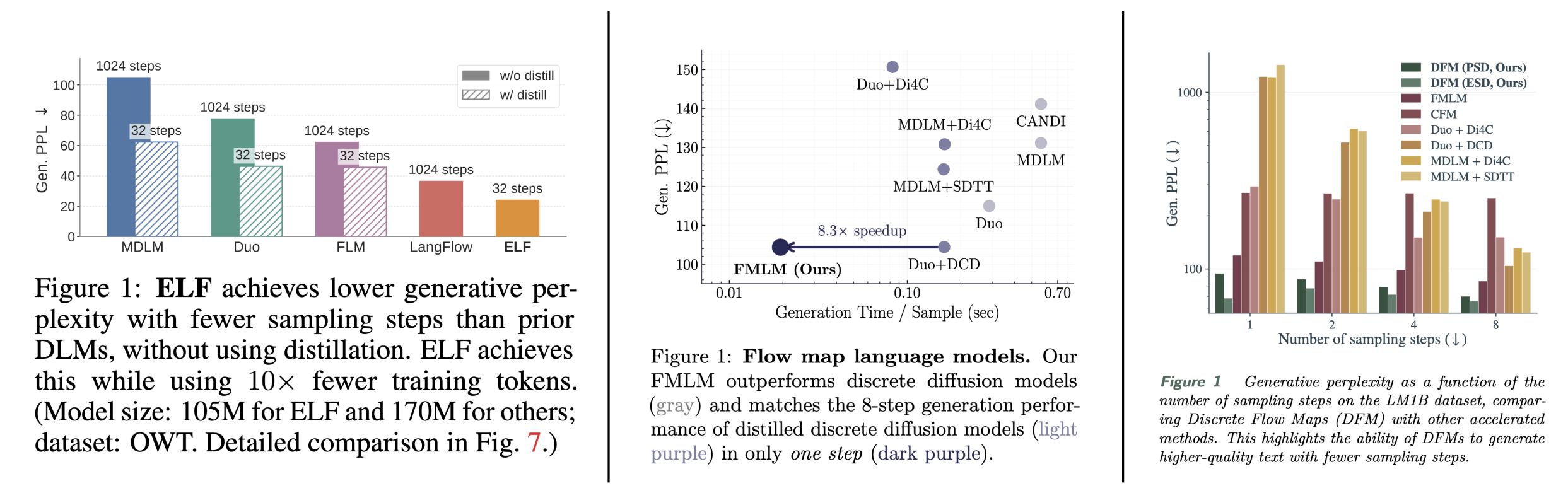
In the three most prominent papers on language modeling with flow models, the main figure (Figure 1) reports gen. PPL without controlling for sample entropy. Above, we showed that:
- It is trivial to improve gen. PPL by decreasing entropy (via sampling temperature)
- Not controlling for entropy leads to bizarre conclusions (like
gpt2-smallis better thangpt2-xl) - So, you should match entropy to recover expected scaling laws
If you buy this argument that you should control for sample entropy, this means that (using the main figures) it is impossible to make any meaningful comparison between the models.
The "improvement" from model to model could very well be coming only from differences in entropy, as demonstrated earlier. Finding the sample entropy of these results to faithfully compare them is left as an exercise for the reader.
Proposal to fix the entropy problem
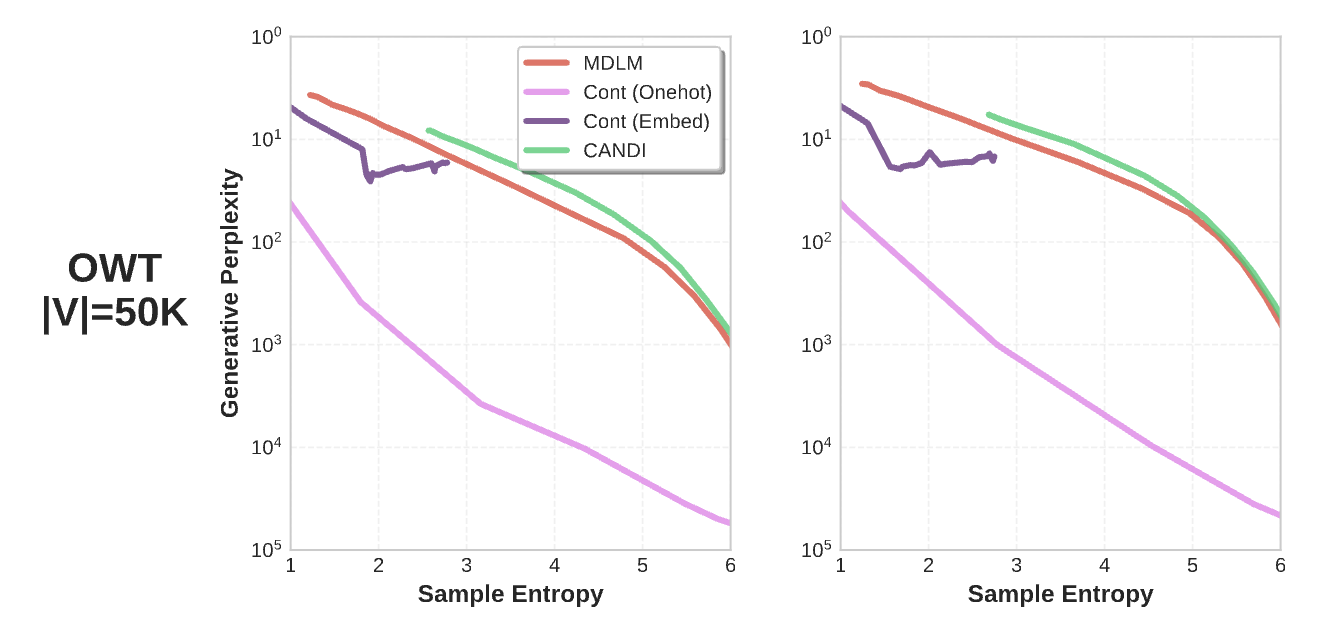
Fixing this entropy-sensitivity problem is straightforward: control for the confounder. One way is to sweep PPL and entropy as we did earlier and include the entire curve in the results, as in CANDI and ELF: Embedded Language Flows (well, ELF reports the frontier for ablations, but the main results do not control for entropy!). If you are reporting a scalar gen. PPL quantity, report interpolated gen. PPL at the entropy of the data. This completely eliminates any variance attributable to difference in entropy.
2. The best-scoring model is not the best language model, but the most gpt2-large-like
Now, if you paid close attention to the previous section, you may have noticed that we never showed that the gpt2-large has better gen. PPL than gpt2-xl when we control for entropy. This is because fixing entropy alone doesn't solve this problem. There is another issue with generative perplexity: the model with the best generative perplexity is not the one that models the data the best, but the one that matches the scorer the best (gpt2-large).
Below, we plot the frontier of generative perplexity versus entropy from sampling the GPT-2 models with different temperatures. We use two different models to score these samples: Pythia 2.8b (left) and gpt2-large (right).
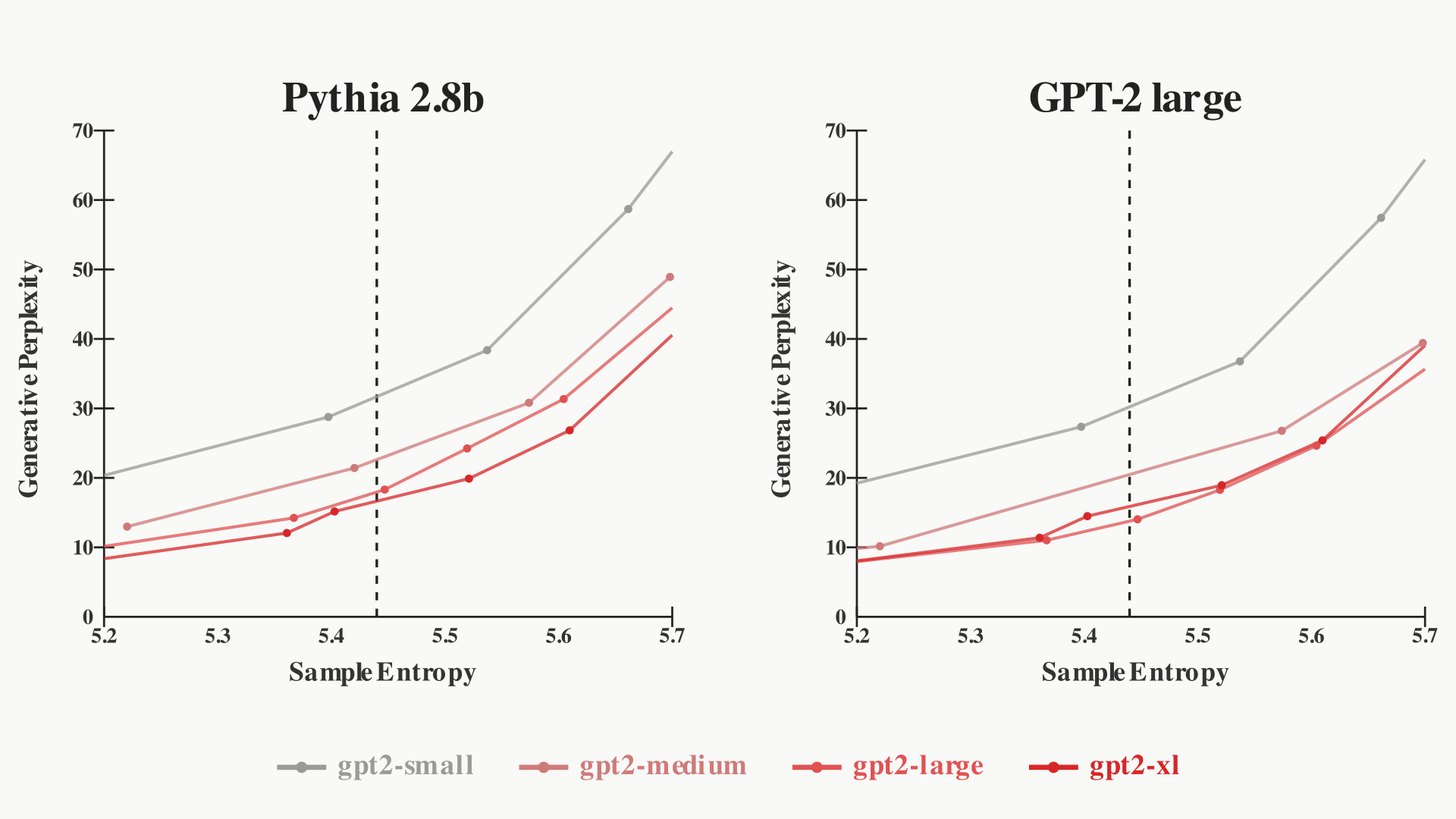
pythia-2.8b (left) and gpt2-large (right) as the scorer. With pythia-2.8b as the scorer, we recover smooth scaling laws. However, with gpt2-large as the scorer, gpt2-large seems better than gpt2-xl.Notice that gpt2-xl has a worse generative perplexity than gpt2-large when the scorer is gpt2-large. This is unsurprising: by definition, the highest probability (lowest gen. PPL) strings are those greedily (t=0) generated by the scoring model, so gpt2-large will be preferential to its own samples. If we instead use a newer (better) model as the scorer -- Pythia 2.8B -- then we recover the smooth GPT-2 scaling laws.
For models that are poor models of the data, it doesn't matter much that gen. PPL rewards gpt2-large-like samples: gpt2-large might as well be an oracle. But as the models improve, this will become more and more of an issue.
Generative perplexity can punish correctness
You can dream up many clear examples to show that the current evaluation is penalizing "correct" behavior. One such example is outlined above: gpt2-xl has a higher gen. PPL than gpt2-large itself despite having better scores on all measured benchmarks.
Here is another: gpt2-large assigns low probability to correct answers of arithmetic problems. Across 1000 randomly-sampled 5-digit multiplication problems, I queried gpt2-large to measure the generative perplexity of two completions: its own greedy (t=0) completion and the correct completion. It is given 50 in-context examples. The histogram of the generative perplexities across the 1000 randomly-sampled problems are shown below. gpt2-large assigns an aggregate PPL of 37.9 to the correct answer, and an aggregate PPL of 11.70 to its own greedy completion which is correct 0% of the time. This means that a model which can do perfect arithmetic would have a much worse generative PPL than a model which matches the incorrect answers of gpt2-large.
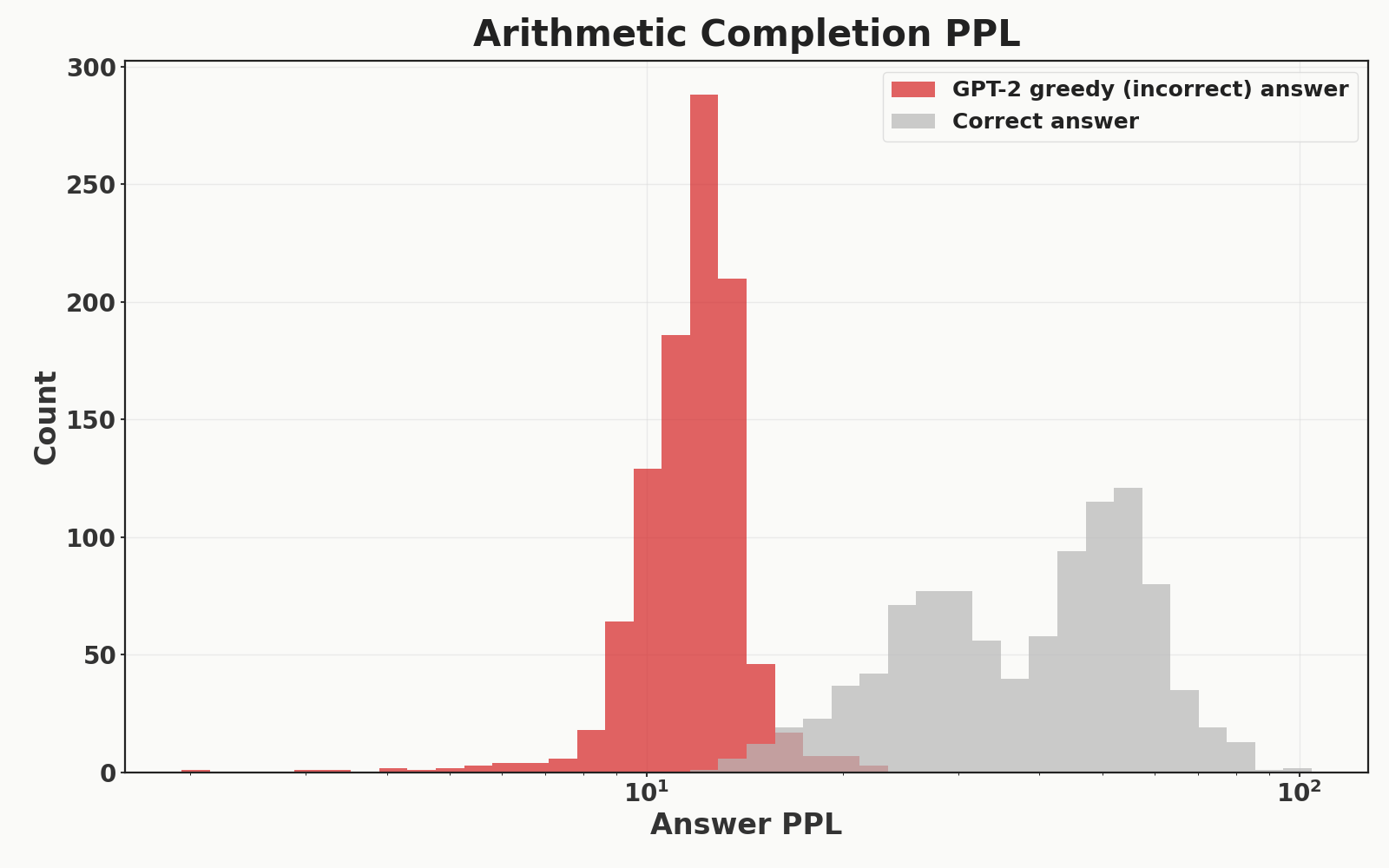
gpt2-large to correct multiplication answers versus its own greedy, incorrect completions across 1000 problems.Generative perplexity is biased towards autoregressive models
Further, since you would expect models with the same architecture/training to have more correlated errors than models with different architectures/training, generative perplexity is architecturally biased towards left-to-right autoregressive transformers (because gpt2-large is a left-to-right autoregressive transformer).
To show this, I trained two 179M parameter autoregressive transformers on OpenWebText: one in the standard left-to-right fashion, and one training from right-to-left (literally just added a [::-1] in the dataloader). For each checkpoint, we run two evals:
- Validation perplexity on held-out OWT data (standard autoregressive validation)
- Generative perplexity under
gpt2-largeat the entropy of the data. To do this, we sweep sampling temperatures like in earlier sections to control for entropy (we sample 512 sequences for each temperature).
A priori, you would expect learning right-to-left to be a bit slower (LEDOM: Reverse Language Model). We can control for this by not just looking at the gen. PPL of a given checkpoint, but looking at the ratio between validation perplexity (gold standard) and gen. PPL at each checkpoint. Any difference in the ratio between validation perplexity and generative perplexity reveals an unwanted generative perplexity bias. This is exactly what we find:
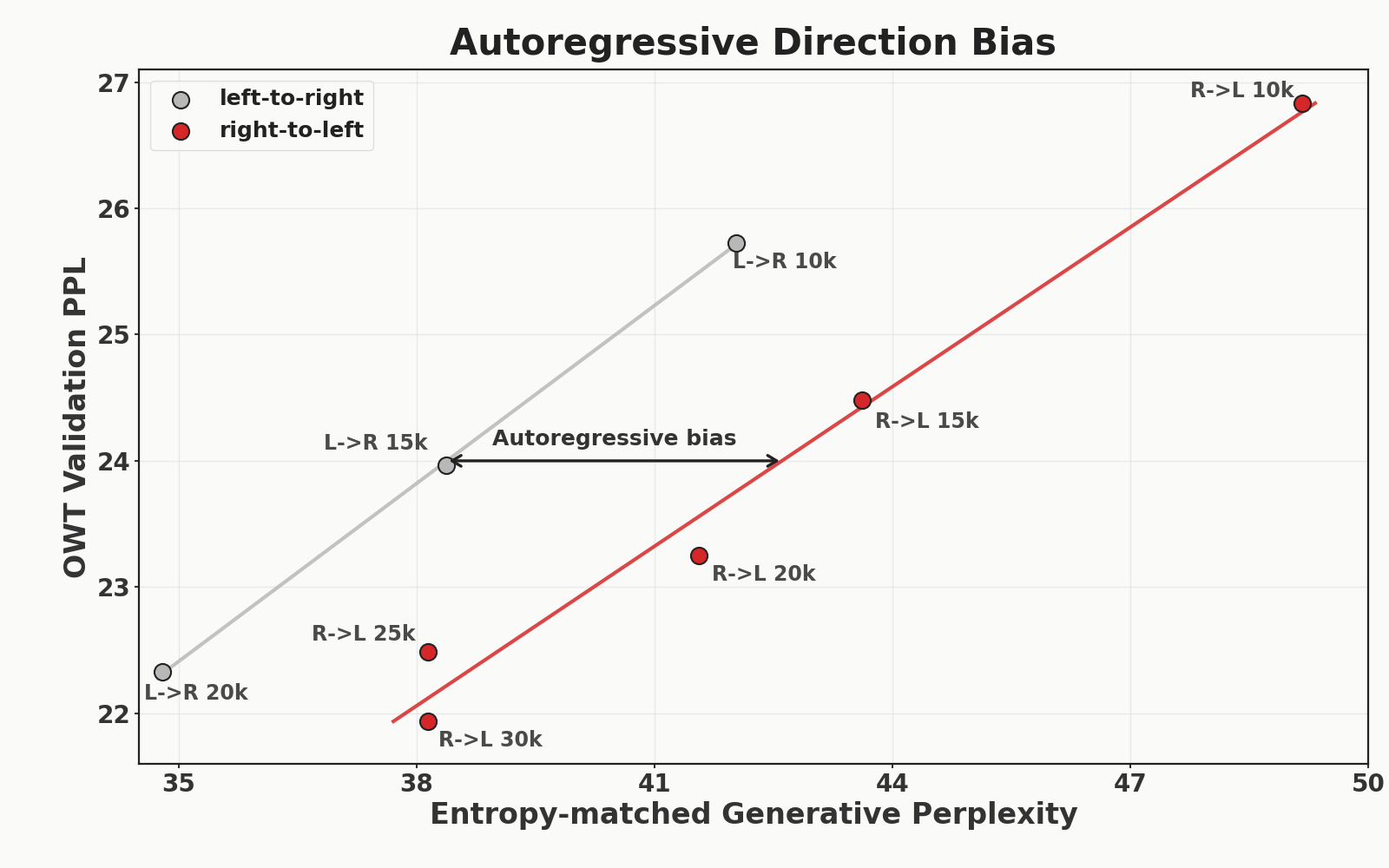
Importantly, we are controlling for the fact that the R->L model learns slower: the 30k R->L checkpoint has a lower validation perplexity loss than the 20k L->R checkpoint, yet its generative perplexity is over 3 nats higher, revealing a bias for left-to-right autoregressive models.
Proposal to fix the gpt2-large bias
Fixing this is not straightforward: it is inherent to the idea of using another model as the ground truth. But, if we are going to treat a language model as the ground truth language distribution, we might as well use the better one: gpt2-xl.
3. Entropy only measures intra-sample diversity: inter-sample diversity is an afterthought
In some recent flow model papers, entropy is referred to as a "diversity" measure. However, this entropy is computed within each generated sequence and then averaged across generated sequences:
\[ \frac{1}{M}\sum_{m=1}^{M} \left( -\sum_{v \in V} \hat p_m(v)\log \hat p_m(v) \right) \]
where \(\hat p_m(v)\) is the empirical frequency of token \(v\) in generated sample \(m\). This means that if a model generated the same exact sequence every sample, and that sequence has low generative perplexity and high entropy, then it would seem like an incredibly strong model under these two metrics .
To give an example, if the model recited the following sequence from OWT every single sample, its PPL would be 4.283 with an entropy of 5.42 -- 10x lower than the entropy-matched SOTA (don't read it, just putting it here to show that generating a single, only-somewhat-coherent sentence is enough to get SOTA gen. PPL/entropy):
Rice, 42, was the highest-ranking officer of the six police officers charged in Gray's arrest and death. Prosecutors had alleged that Rice and others caused Gray's death by failing to secure him in a seat belt in the back of the van, where Gray suffered severe spinal cord injuries last year.
Rice was suspended without pay from May 1, 2015, when he was charged by the state's attorney's office, until July 18 of this year, when Circuit Judge Barry Williams found Rice not guilty of all charges.
"Being suspended without pay for over a year has been financially devastating to Lt. Rice and his family," said Michael Belsky, Rice's attorney.
Williams said prosecutors failed to meet their burden of proving the charges against Rice beyond a reasonable doubt, instead asking the court to rely on "presumptions or assumptions" — something it cannot do. He said the court "cannot be swayed by sympathy, prejudice or public opinion."
CAPTION Baltimore State's Attorney Marilyn Mosby talks about why her team decided to drop the charges against the officers in the Freddie Gray case. (Kevin Richardson/Baltimore Sun video) Baltimore State's Attorney Marilyn Mosby talks about why her team decided to drop the charges against the officers in the Freddie Gray case. (Kevin Richardson/Baltimore Sun video) CAPTION "I think most of the blame falls to the prosecutor who failed to prosecute the case and brought cases that she didn't have the evidence for," Gov. Larry Hogan said. (Erin Cox/Baltimore Sun video) "I think most of the blame falls to the prosecutor who failed to prosecute the case and brought cases that she didn't have the evidence for," Gov. Larry Hogan said. (Erin Cox/Baltimore Sun video)
Mayor Stephanie Rawlings-Blake has said Rice now faces an administrative review.
Gray, 25, died April 19, 2015, one week after his arrest. His death sparked weeks of protests and activism against police brutality, and two nights of looting and rioting.
Last month, the spending panel authorized $87,705 in back pay for Officer Caesar Goodson Jr., the driver of the van in which Gray sustained his injuries. He, too, was cleared of all charges at trial. Williams also acquitted Officer Edward Nero, and prosecutors dropped all charges against the other three police officers.
Lbroadwater@baltsun.com
Twitter.com/lukebroadwater<|endoftext|>MIAMI, August 9 – The Miami HEAT announced their 2016-17 preseason schedule today, which is highlighted by the team’s three home games at AmericanAirlines Arena. The HEAT will open the preseason on the road on Tuesday, October 4, when they take on the Washington Wizards at 7PM. They will make their first appearance in Miami a week later, when they host the Brooklyn Nets at 7:30PM on Tuesday, October 11. They will also face off with the Orlando Magic in Miami on October 18 at 7:30PM, and conclude the home preseason schedule vs. the Philadelphia 76ers on October 21 at 7:30PM.
Tickets for the three home games at AmericanAirlines Arena are on sale now and can be purchased by logging on to HEAT.com, Ticketmaster.com, by visiting any Ticketmaster outlet, or by calling 1-800-4NBA-TIX. Tickets can also be purchased at the AmericanAirlines Arena Ticket Office Monday through Friday from 10AM to 5PM. Ticket prices start at $10 plus applicable fees.
In addition to the three home games at AmericanAirlines Arena, the HEAT will host two neutral site games vs. the Minnesota Timberwolves. Miami returns to the Sprint Center in Kansas City, MO, for the sixth time on October 8. Tickets to that game are available by visiting SprintCenter.com, Price Chopper Box Office at Sprint Center or by calling (888) 929-7849. The HEAT will also return to the KFC Yum! Center in Louisville, KY, for the third straight season, on October 15. Tickets are available at the KFC Yum! Center Box Office, all Ticketmaster outlets, Ticketmaster.com or by calling (800) 745-3000. Miami will also play road contests against the San Antonio Spurs on October 14, and the Charlotte Hornets on October 21.
The complete broadcast schedule for the preseason will be released at a later date.
The preseason schedule is as follows:
DATE OPPONENT LOCATION TIME TICKETS Oct. 4 at Washington Verizon Center, Washington, DC 7:00 PM Oct. 8 vs. Minnesota Sprint Center, Kansas City, MO 7:30 PM Oct. 11 vs. Brooklyn AmericanAirlines Arena, Miami, FL 7:30 PM Buy Tickets Oct. 14 at San Antonio AT&T Center, San Antonio, TX 7:30 PM Oct. 15 vs. Minnesota KFC Yum! Center,
A model that repeats this one OWT excerpt every sample can still land in a strong-looking gen. PPL / entropy region, despite having no inter-sample diversity.
Obviously, this example is very unlikely to occur in any reasonable setup. The point is that entropy is not measuring diversity of samples at all, only diversity within a sample. There could very well be a tradeoff between sample diversity and gen. PPL, just like there is a tradeoff between sample entropy and gen. PPL.
Proposal to measure inter-sample diversity
Flow Map Language Models reports self-BLEU scores (geometric average of ngram overlap) in the appendix. This is a clear improvement and will flag mode collapses, but now interpretation of results relies on 3 variables instead of the (already problematic) 2: gen. PPL, per-sample entropy, and self-BLEU.
So, report self-BLEU scores if you are going to report generative perplexity and entropy. But, as discussed in the next section, there are cleaner, bigger changes which can and should be made.
The fixes
As mentioned throughout, there are ways to somewhat ameliorate the three discussed issues: report the entropy vs. generative perplexity frontier, use gpt2-xl as the scorer, and report self-BLEU.
However, these are patching a framework that becomes more problematic as the models get better. The field is already moving towards two ways of evaluating flow models that are more robust and easy to interpret: validation perplexity upper bounds and downstream metrics. I hope that future works report these as main results instead.
Derive and report PPL bounds
Recently, LangFlow derived a validation perplexity bound for their model. Calculating PPL bounds on real data sidesteps all of the outlined problems. One issue is that calculating this PPL bound is quite slow, new models must derive their own PPL bounds, and the gap between the upper bound and the true PPL is unknown. Work in this area (faster, more general, tighter bounds) is great.
Focus on downstream metrics
Why do we care about validation PPL in the first place? On one hand, it is very natural: we are training generative models of the data, and validation perplexity is a monotonic function of the probability of the data under our model. Also, it is quite interpretable: it gives the effective number of equally likely next-token choices implied by the model's average log loss. On the other hand, we want these models to do useful things: solve problems, answer questions. So, by focusing on these downstream metrics which only require drawing samples, we can go beyond this gen. PPL fixation (to be fair, pretraining perplexity is very predictive of downstream performance and much cheaper to calculate). Flow Map Language Models does this well by reporting Sudoku results in addition to their gen. PPL results.
Open questions
In writing this up, there are a few things I couldn't get a satisfying answer to.
1. Why are flow model gen. PPL scorers largely independent of the scorer
If we generate tokens with a list of models and score them with every model, we get the plot below (left). Note that this confounds sample entropy and does not control for the problem in Section 1.
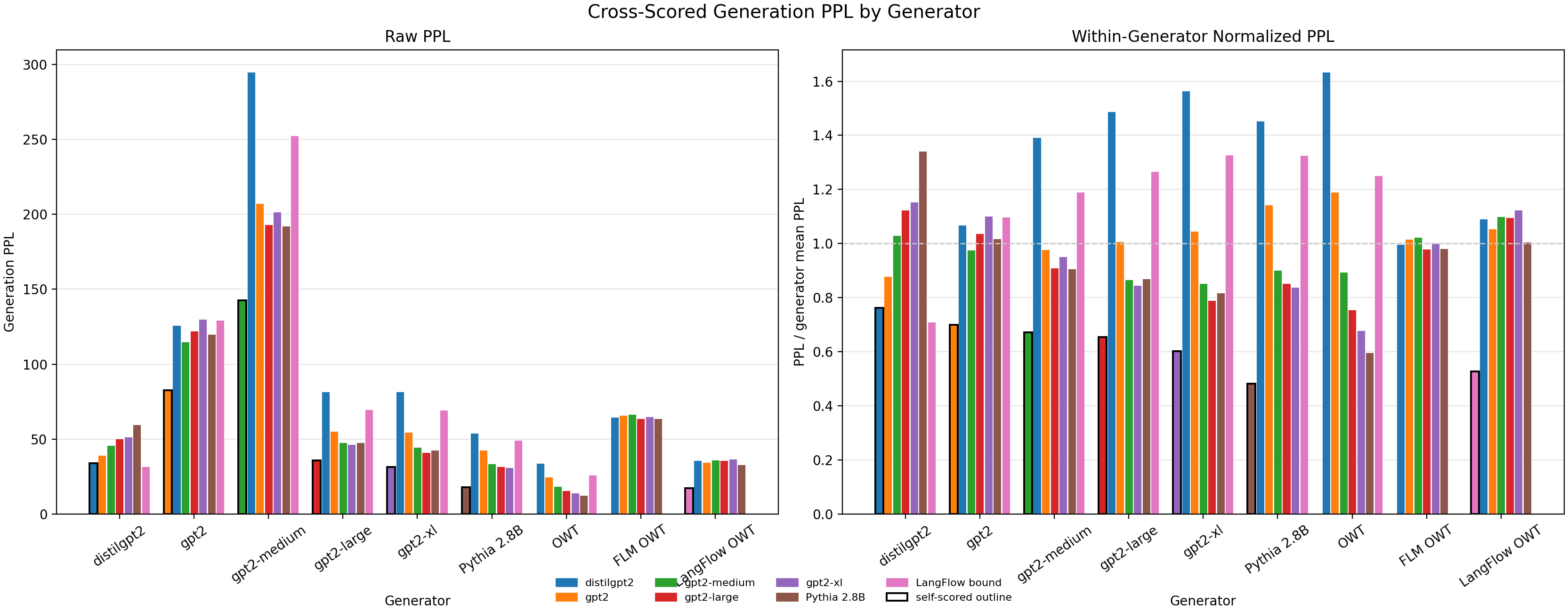
As you can see, there is lots of variance across the scorers for a given generator for all but 3 models: gpt2, FLM, and LangFlow.
Why is this? I ran per-token scoring and for these models, it isn't that there is more agreement per token (lower variance), but rather that the disagreement is there (high variance) but it seems to cancel out when averaged across tokens. I don't have an intuitive explanation for why this is or what it means.
2. What is the best way to tradeoff entropy v. ppl in flow models?
In autoregressive models and (some) masked diffusion models, it is trivial to tradeoff entropy and gen. PPL: just change the temperature. However, in a flow model, I'm not sure what the relevant lever to pull is.